The Reasoning Models Substack - Issue #7
Claude 3.7 Sonnet and ChatGPT 4.5 prove (still) nobody knows how to name reasoning models yet 🤪

Last week was a big one in the Reasoning Models world as the two biggest companies released their new reasoning models, and, for the first time, both didn’t impress as much as people had hoped.
Yes, it’s a bit of a bummer but not a surprise, as time goes on, these incremental model updates aren’t coming with the same breakthrough results as earlier versions, and in the case of last week, they’re actually a step backwards for some use-cases.
But we were warned.
OpenAI would like you to know that its new GPT-4.5 model, released yesterday, is going to suck.
That might seem like a strange marketing message from one of the world’s most exciting companies, but that’s essentially what OpenAI CEO Sam Altman said about the release of the 4.5 model.
On social media, Altman was quick to point out that the model is not a new frontier model. At best, it’s a small tweak — an iterative improvement to OpenAI’s flagship GPT-4 model.
“A heads up: this isn’t a reasoning model and won’t crush benchmarks,” Altman wrote when announcing the release. Altman also said “bad news: it is a giant, expensive model” (Source - Medium)
Yes, Sam was honest with all of us, which I appreciate, although I’m not sure this message made its way to everyone as I’ve seen more and more people share their lackluster results with ChatGPT 4.5 online.
For me, I ran into a strange issue where I just could not, not matter how hard I tried, get 4.5 to produce an image of a man that wasn’t wearing glasses. I would literally tell it, okay, that last image the guy is wearing glasses, can you product an image where he’s not wearing glasses. And well, you can just see for yourself ⬇️



So yeah. Sam was right in some respects, but drawing cartoons of people not wearing glasses isn’t what most people use ChatGPT for so how important is this really? What people really want to see, and what I personally use ChatGPT for the most is coding, and it did pretty darn well there.
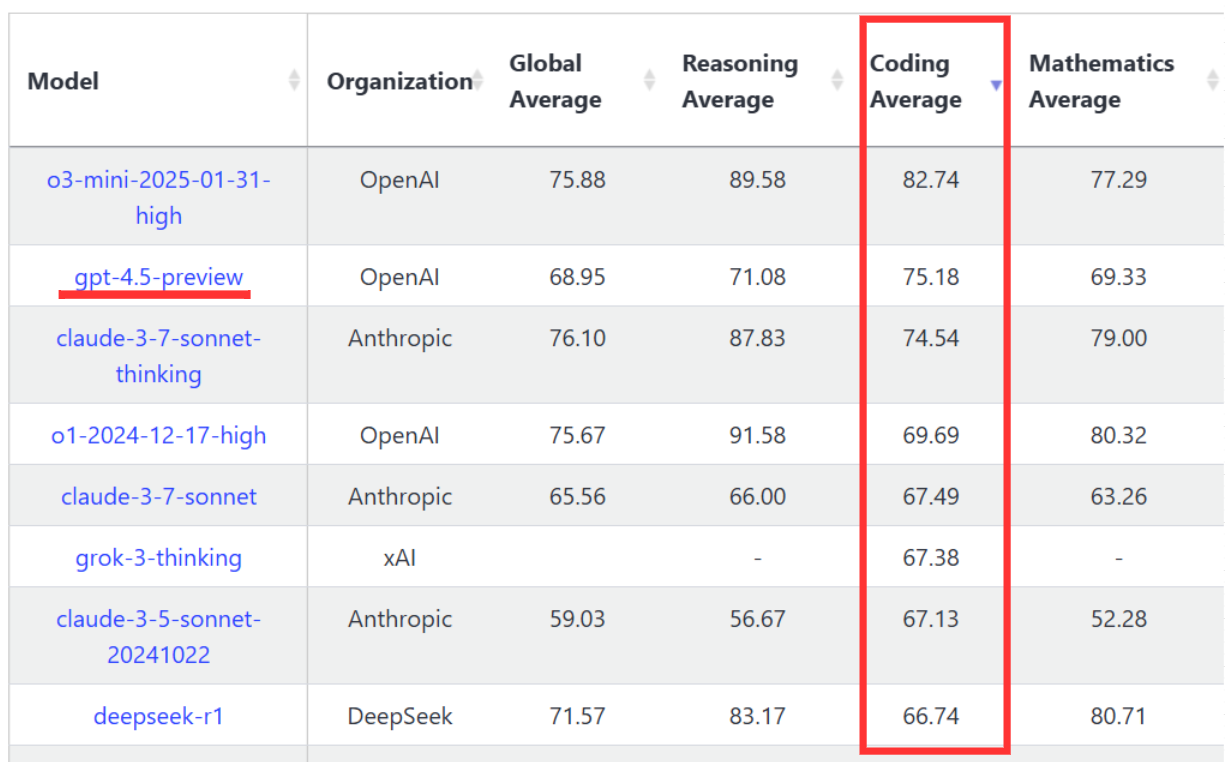
While not as good as o3-mini, it 4.5 benchmarked on par with Claude 3.7 Sonnet, which is what I’m going to talk about next. So let’s talk Claude, and what I think was actually the biggest announcement last week - Claude Code.

So first, let’s address the elephant in the room, we all thought Anthropic was going to announce Claude 4 Sonnet, so the 3.7 threw us for a loop. At the same time, I think they made the right move here, if you’re not going to solve your naming problem, go deep into randomness 😵💫
Since it was announced, Claude 3.5 Sonnet has been the go-to model for coding so myself, and many other developers around the world were pretty darn excited for the next evolution of this model. And the benchmarks, well here they are:

So yes - excitement deserved with a noticeable improvement in the software engineering performance over Claude 3.5. As you can also see from the chart above, while Claude 3.5 was in the lead initially, everyone else caught up. And as you saw from the chart I shared at the beginning, ChatGPT 4.5 caught up, in the same week so these two are now back to being neck-and-neck.
I’m not going to go into much more detail on ChatGPT 4.5 or Claude 3.7 Sonnet because you can read about both online, but I will share an article about each, not written by the companies themselves that I would recommend ⬇️
Vibe coding with Claude 3.7, ChatGPT 4.5 and o3-mini: a real-world experiment
ChatGPT 4.5 vs. Claude 3.7 Sonnet: Next Generation of Language
Okay, but what I’m the most excited about from last week’s announcement isn’t actually any of the reasoning models themselves, and not because they aren’t cool, but because incremental improvements just aren’t that exciting. What is exciting, to me is new products that allow us to do things differently and that’s where I think Anthropic really won the day with Claude Code.

Claude Code went into Research Preview last week, and well, within 24-hours they hit capacity so while some lucky people got to jump in and play around with it, many are still waiting for their chance.
Here’s the TL;DR from Anthropic on Claude Code because who will explain this better than them?
Since June 2024, Sonnet has been the preferred model for developers worldwide. Today, we're empowering developers further by introducing Claude Code—our first agentic coding tool—in a limited research preview.
Claude Code is an active collaborator that can search and read code, edit files, write and run tests, commit and push code to GitHub, and use command line tools—keeping you in the loop at every step.
Claude Code is an early product but has already become indispensable for our team, especially for test-driven development, debugging complex issues, and large-scale refactoring. In early testing, Claude Code completed tasks in a single pass that would normally take 45+ minutes of manual work, reducing development time and overhead.
In the coming weeks, we plan to continually improve it based on our usage: enhancing tool call reliability, adding support for long-running commands, improved in-app rendering, and expanding Claude's own understanding of its capabilities. (Source - Anthropic)
A lot of people have commented that Claude Code living in the terminal is a bit odd…but I think this is just the starting point, seeing a full-featured IDE from Anthropic that competes head-to-head with Cursor and Windsurf feels like an inevitability at this point.
And with that, I’ll leave it there as I know this is already a lot to take in, and with the reasoning models space moving so far, there will be even more to talk about in the coming weeks. For now - enjoying playing around with Chat GPT 4.5 and Claude 3.7, and get on that waitlist for Claude Code if you haven’t already, it’s definitely worth the wait.
Thanks for reading and I’ll see you next time!